안녕하세요.
오늘은 제가 후에 Real-time Segmentation SOTA paper를 읽을 때
필요한 baseline paper라고 선정한 논문들의 Background, Method, Experiment를 간단하게 정리해보겠습니다.
순서는 타이틀과 같이 PSPNet, ICNet, ENet 순으로 하겠습니다.
1. PSPNet
Zhao, Hengshuang, et al. "Pyramid scene parsing network."
Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
(논문 링크: https://arxiv.org/abs/1612.01105)
KeyWord: Global Context Information
- Backgrounds
FCN model을 대표로 기존 Segmentation model들의 문제점들을 그림 1과 함께 살펴보겠습니다.
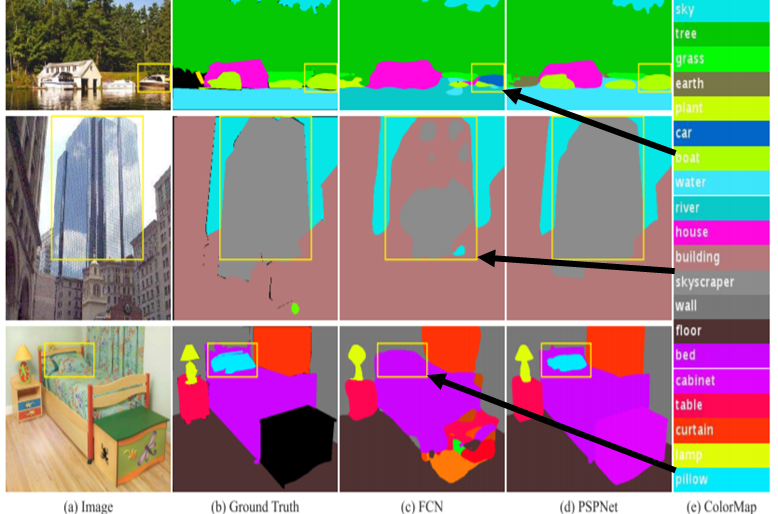
1. 강가에 위치한 보트를 자동차로 잘못 인식하는 것처럼 주변 상황을 고려하여 클래스를 분류하지 못하는 Mismatched Relationship
2. 비슷하게 생긴(비슷한 특징을 가진) 건물(Building)과 초고층 건물(SkyScraper)을 명확하게 분류하지 못하는 Confusion Categories
3. 침대와 같은 패턴을 가져 눈에 잘 띄지 않는 Obejct인 베개(Pillow)와 침대(Bed)를 명확하게 분류하지 못하는 Inconspicuous Classes
이렇게 대표적인 3가지 문제점이 있습니다.
- Method
이 문제점들을 해소하기 위해, PSPNet은 2x2 Average Pooling을 사용한 Gloal Context Information을 제안했습니다.
(Max Pooling보다 Average Pooling이 성능이 더 잘 나왔다고 본 논문에 작성되어 있어 Average Pooling에 대한 방법만 간단하게 설명하도록 하겠습니다.)
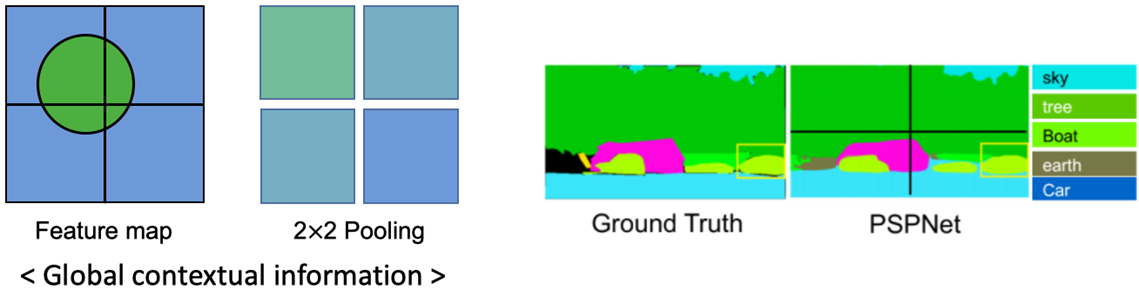
그림 2의 좌측 예시를 보면서 설명하면,
각 4개의 sub-region에 해당하는 pixel 값들의 평균을 오른쪽 2x2 배열에 입력하면
우측 그림과 같이 근처에 물이 있는지 주변에 대한 feature 정보를 얻어 앞선 예제인 FCN처럼 차가 아닌 보트로 최종적으로 예측할 수 있게 됩니다.
이 Global Context Information을 네트워크에 적용하고 수행하는 Task를 살펴보겠습니다.
- Network

1. 먼저, 이미지로부터 dilated CNN을 수행한 feature map을 획득합니다.
2. 획득한 feature map에 대하여 각 다른 크기의 Average Pooling을 수행합니다.
3. 각 feature map에 bilinear interpolation과 1x1 convolution을 수행하여 feature map들의 size와 channel 수를 맞춰준 다음, 모두 더하여 최종 Prediction을 획득합니다.
- Conclusion
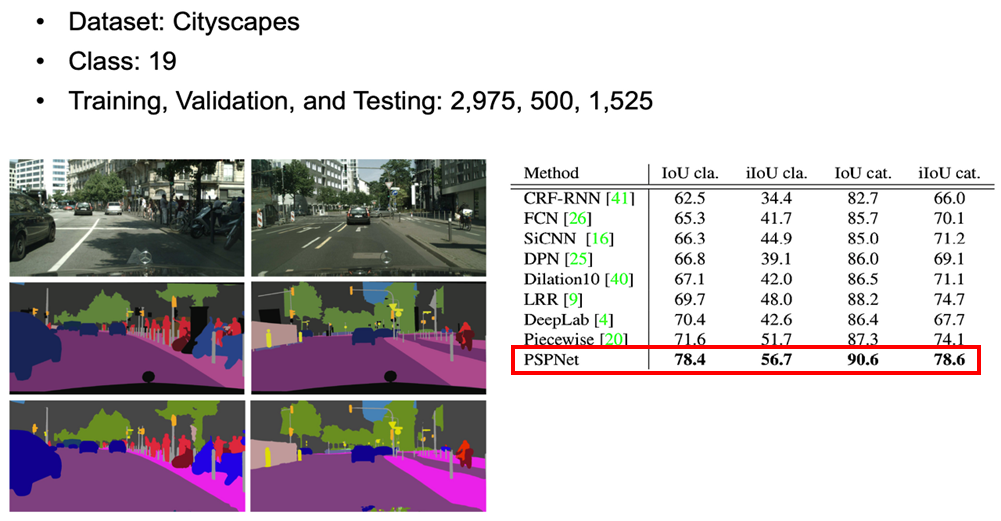
위 PSPNet architecture에 Cityscapes 데이터셋을 적용하면
기존 Segmentation model들보다 Accuracy가 높아진 것을 확인할 수 있습니다.
2. ICNet
Zhao, Hengshuang, et al. "Icnet for real-time semantic segmentation on high-resolution images."
Proceedings of the European Conference on Computer Vision (ECCV). 2018.
(논문 링크: https://intuitive-robotics.tistory.com/79)
Keyword: CFF(Cascade Feature Fusion), Cascade Label Guidance
- Background
ICNet과 동일한 저자들인 PSPNet 저자들은
PSPNet이 높은 Accuracy를 보이지만 낮은 처리 속도를 갖는 문제점이 많은 연산량으로 인한 속도 저하라 생각하여
Input과 kernel로 Convolution 연산을 수행하여 Output을 획득하는 Convolution 수식을 분석하며
Input, Output, Kernel의 연산량을 집중적으로 살펴보았습니다.
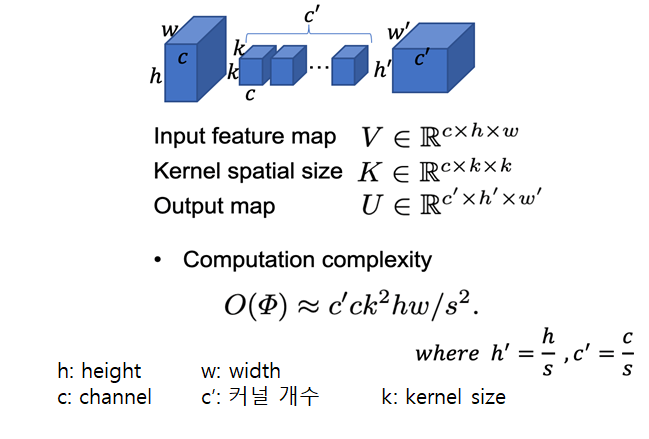
Feature Extraction을 하기 위해 Convolution 연산을 수행할 때,
커널의 크기는 사이즈는 최소 3x3을 가지므로 저자들은 커널이 아닌 input 사이즈를 조정해보기로 합니다.
- Network
그래서 저자는 layer 개수가 각기 다른 3-branch Network Architecture를 제안하였습니다.
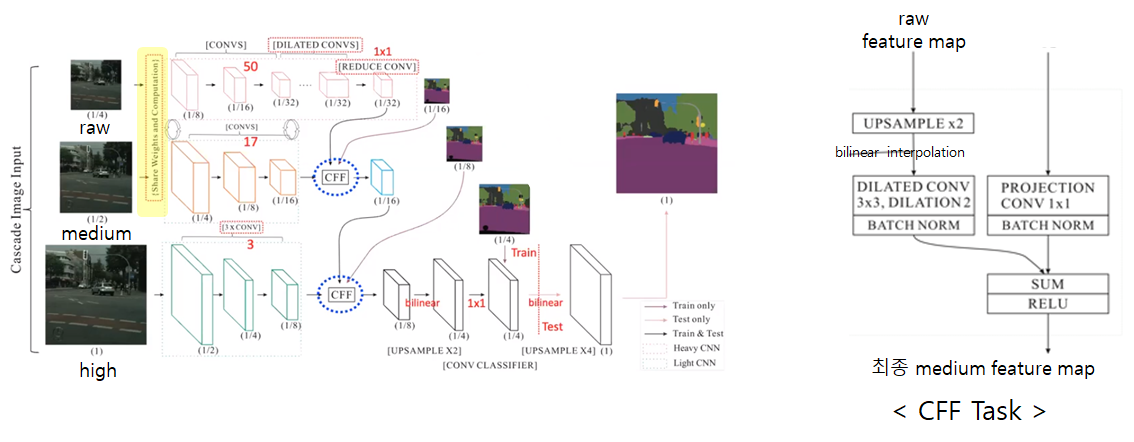
Network의 Task를 간단하게 살펴보겠습니다.
1. 각 branch에 입력 이미지의 원본, 1/2, 1/4 사이즈를 각각 넣는데 편하게 high/medium/raw resolution이라 칭하겠습니다.
2. raw branch는 50개의 layer를 갖는 기존 PSPNet을 통과하여 global한 정보를 획득합니다.
medium barnch는 연산량을 줄이기 위해 raw resolution과 share하는 weight를 사용하며 기존 PSPNet의 17개 layer만 통과합니다.
high branch는 아주 얕은 3개의 layer만을 통과하여 local한 정보를 획득합니다.
3. 각 branch에서 획득한 feature map을 CFF(Cascade Feature Fusion)으로 fusion합니다.
이 CFF의 task를 raw branch에 대하여 설명하면 오른쪽 그림과 같이
raw branch의 최종 feature map을 upsampling하여 medium branch의 feature map의 크기에 맞춥니다.
Upsampling을 수행한 feature map에 dilated Convolution을 수행하여 upsampling 과정 중 손실된 정보를 다시 획득합니다.
medium branch의 feature map과 채널 수를 맞추기 위해 1x1 convlution을 수행하고 batch normalization과 summ을하여 최종적인 medium feature map을 획득합니다.
그리고 이 feature map을 획득할 때 loss도 함께 계산을 해줍니다.
- Loss Function
이 Network에서 loss를 계산하는 과정을 Cascade Label Guidance라고 합니다.
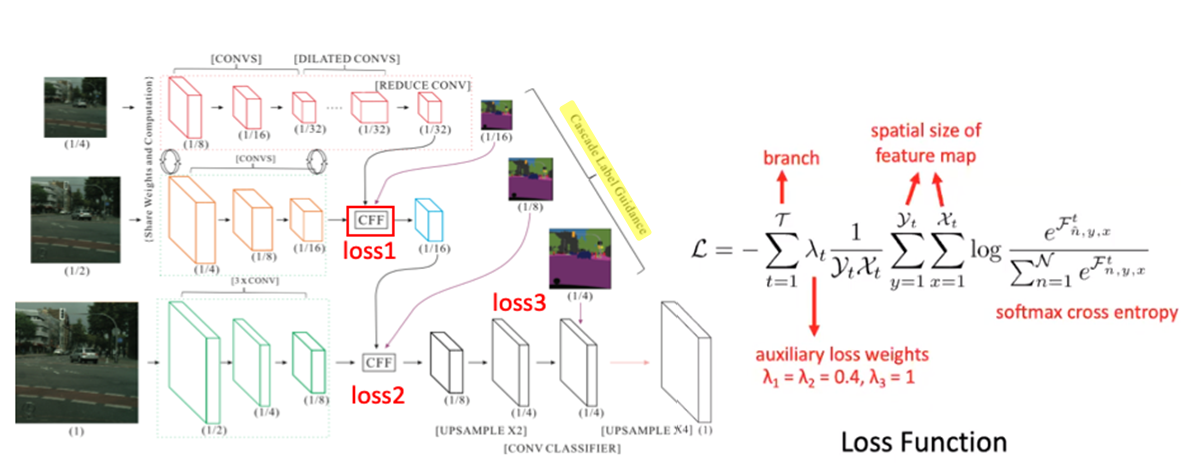
Cascade Label Gudiance라 칭하는 loss function의 수행을 보면,
loss를 최종 단에서만 계산하는 것이 아닌
각 branch의 feature map과 중간중간에 이미지를 resize한 GT를 비교하여 각 loss를 계산하여 3개의 loss를 구합니다.
각 loss에 람다라는 파라미터로 각자 다른 가중치를 임의로 곱해주는데
그 이유는 가중치를 각자 다르게 곱함으로써 각 branch가 학습이 더 잘될 수 있도록 하고
특정 branch가 Training 결과를 dominate하지 않도록 할 수 있습니다.
이렇게 나온 각 loss들을 모두 더한 결과가 total loss로 사용됩니다.
하지만 test 같은 경우, 이미지의 GT를 모르기 때문에 중간 loss들을 구할 수 없어 마지막 단에서만 loss를 계산합니다.
- Conclusion
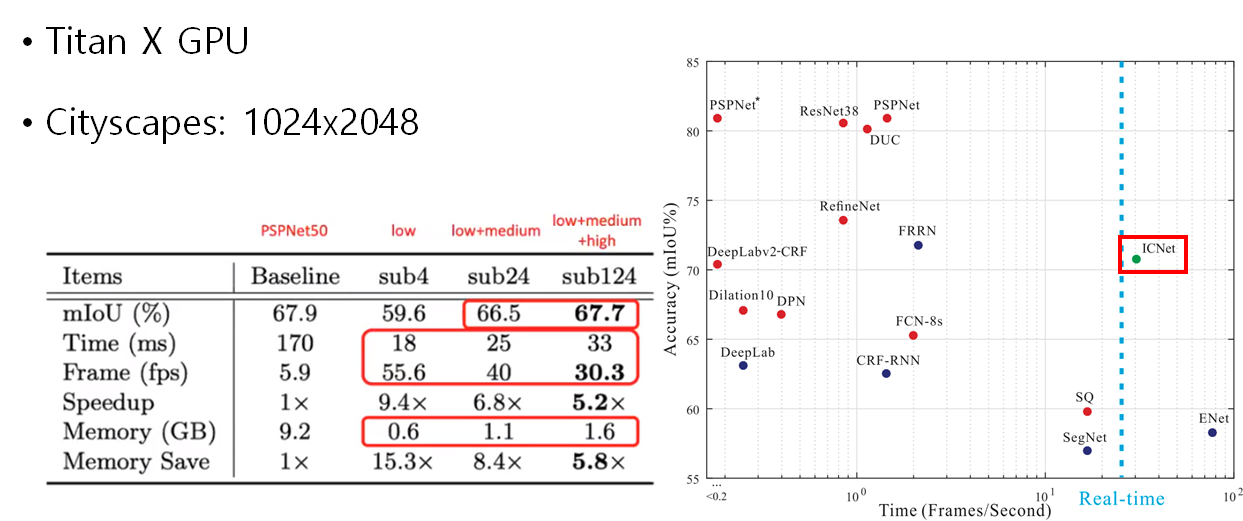
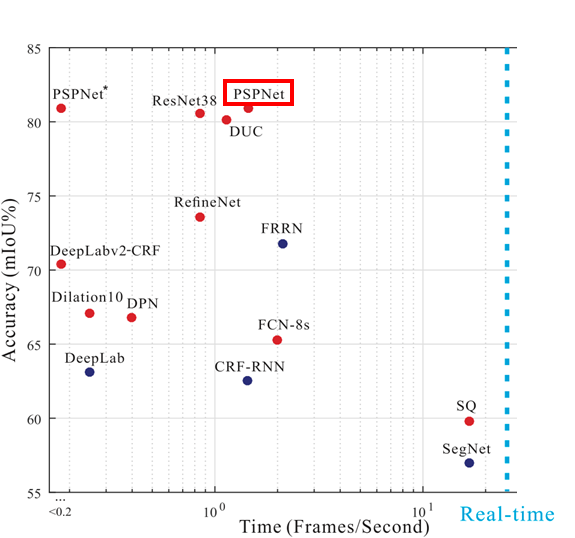
결과적으로 TiTan X GPU 기준으로 PSPNet보다 성능은 떨어지지만
당시 논문 중 가장 좋은 성능을 갖는 Real-time Semantic Segmentation 모델이 되었습니다.
3. ENet
Paszke, Adam, et al. "Enet: A deep neural network architecture for real-time semantic segmentation."
arXiv preprint arXiv:1606.02147 (2016).
(논문 링크: https://arxiv.org/abs/1606.02147)
Keyword: Encoder-Decoder, bottleneck, assymetric/dilated convolution
- Background
당시 Segmentation model(SegNet, ..)들은 portable한 device들에 적용시키기에
많은 부동 소수점 연산을 수행하고 정확도를 향상시키기 위하여 후처리를 수행함으로써 오랜 시간이 걸리는 단점이 있었습니다.

그래서, ENet은 후처리를 수행하지 않음으로써 빠른 inference와 높은 정확도에 최적화된 Encoder-Decoder architecture를 제안했습니다.
- Network
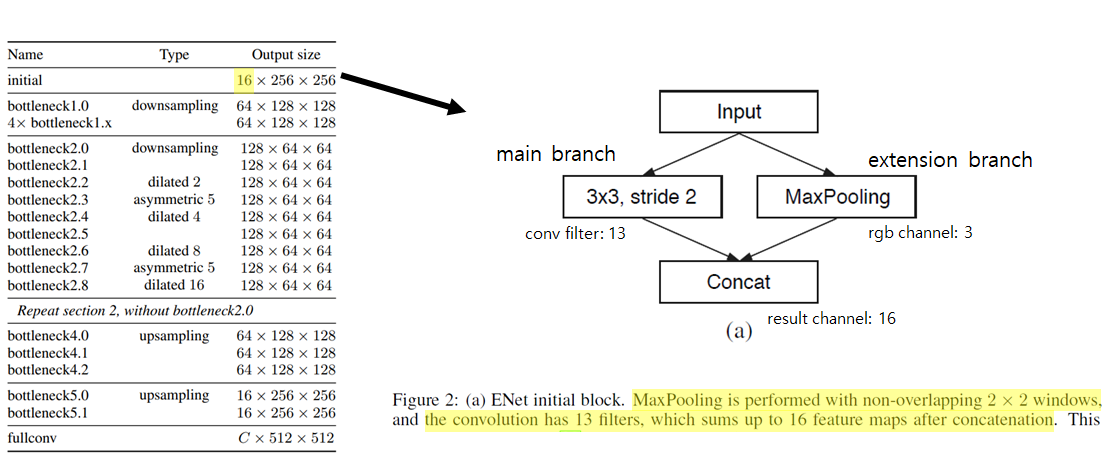
(a) Initial Block은 2개의 branch로 구성되어 있는데,
main branch는 3x3 convolution을 수행하고 extension branch는 non-overlapping한 max pooling을 수행합니다.
Main branch는 3x3 conv를 13번 수행하여 13개의 채널을 갖고
Max pooling branch는 RGB 채널 즉, 3개의 채널을 가지므로
이 둘이 concat하면 16개의 채널을 가지므로 왼쪽 테이블 표에서 16x256x256 Output Size를 갖게 됩니다.
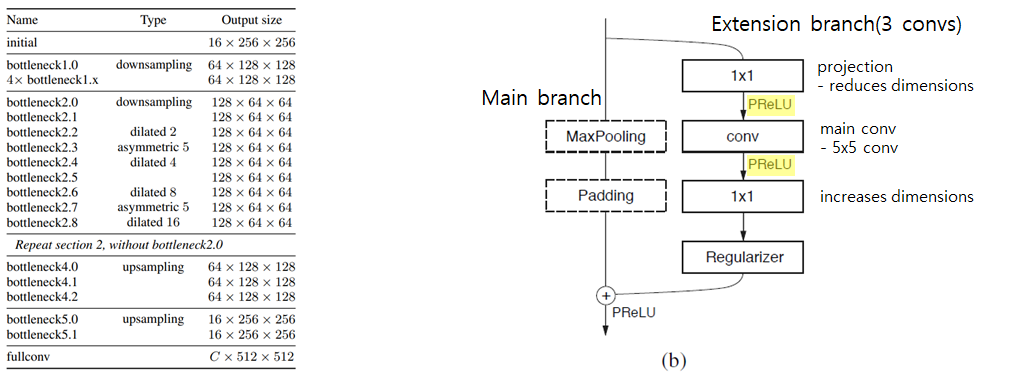
(b) Bottleneck block은 ENet architecture의 main block으로,
down-sampling의 정보를 더 효율적으로 처리하기 위한 Skip connection 형태를 가진 2 branch로 구성되어 있습니다.
Main branch는 입력에 대하여 Max Pooling과 Padding 연산을 수행하고
Extension branch는 Encoder-Decoder 형태를 갖는 3개의 conv layer로 구성되며, ReLU를 사용했을 때
결과가 좋게 나오지 않아 음의 기울기도 학습하는 PReLU를 사용했더니 결과가 잘 나왔으므로 PReLU를 사용했습니다.
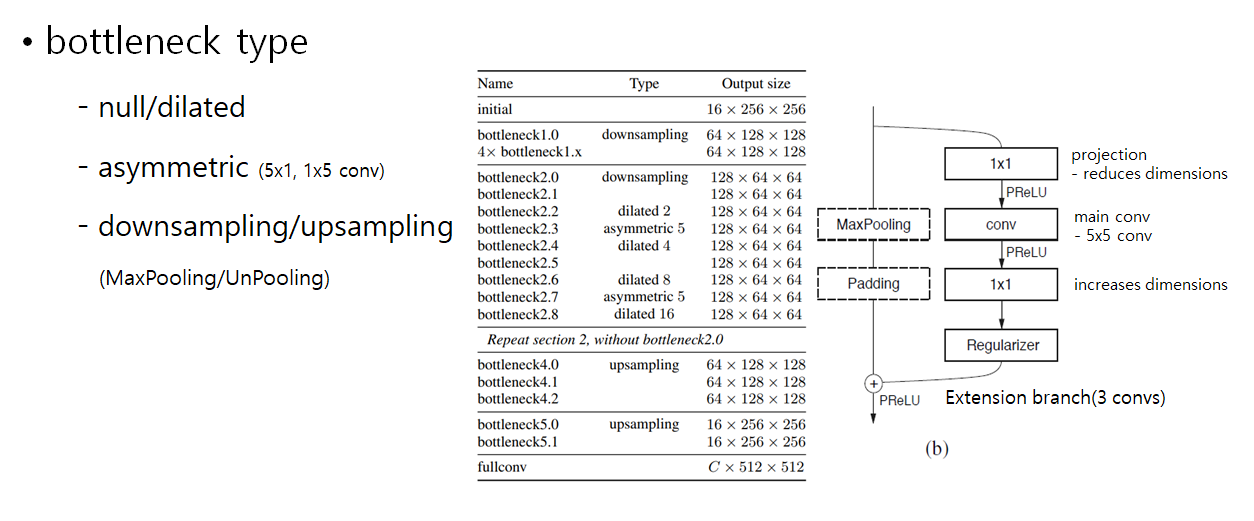
Bottleneck block은 총 5개의 타입을 가집니다.
null/dilated, asymmetric은 Extension branch만 수행합니다.
(dilated는 receptive field를 넓게 가져 좀 더 많은 feature 정보를 얻기 위해 사용되었고
asymmetric은 nxn convolution 연산을 nx1, 1xn으로 나누어 수행하여 중복된 연산을 피할 수 있습니다.)
downsampling, unsampling은 Extension branch와 MaxPooling/UnPooling을 수행하는 main branch를 각각 수행하여 합칩니다.

그래서 결과적으로, 이 네트워크는 위와 같은 block들을 포함한 Encoder-Decoder 구조를 가지며
Encoder는 stage 1~3로,
이미지 사이즈를 줄이면서 feature extraction을 수행하고,
큰 이미지를 처리하는데 많은 비용이 드는 것을 고려하여 stage 3에서는 downsampling을 수행하지 않았습니다.
그리고 과한 이미지 축소는 정보 흐름을 방해할 수 있으므로 Encoder를 3개의 stage로만 구성하여 inference time을 약 10배 빠르게 했습니다.
Decoder는 stage 4,5로,
Encoder의 feature map에 upsampling을 수행하여 세부 정보를 조정하는 것을 수행했습니다.
- Experiment

그래서 결과적으로 ENet은 기존 Segmetation model의 대표 모델인 SegNet보다 속도는 향상되었지만, Accuracy는 많이 하락했습니다.
< Reference >
PSPNet: https://blog.airlab.re.kr/2019/11/pspnet
ICNet: https://intuitive-robotics.tistory.com/79%E3%84%B7
ENet: https://go-hard.tistory.com/74
'Deep Learning > Segmentation' 카테고리의 다른 글
| [Real-time Segmentation] YOLACT: You Only Look At Coefficients (0) | 2021.02.03 |
|---|---|
| [Instance Segmentation] Mask R-CNN (0) | 2021.01.21 |
| [Semantic Segmentation] FCN: Fully Convolutional Network (0) | 2021.01.21 |