
[Object Detection] R-CNN: Regions with CNN features
논문 리뷰로 블로그 첫 포스팅을 하게 되었네요:)
현재 Computer Vision에 대한 연구를 진행하고 있는데 '이에 보탬이 되고자하는 배경 지식을 쌓아보자'하여
딥러닝 기술이 적용된 Object Detection 모델인 R-CNN부터 논문 리뷰를 하며
다양한 논문을 차례로 읽는 것을 목표로 하고있습니다.
논문에 들어가기 앞서 Image Classification을 하는데 기존에 사용한 방법 두 가지를 간단하게 보면

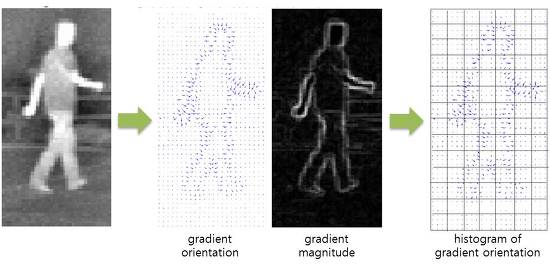
SIFT는 물체의 크기나 회전에 불변하는 지역적인 feature들을 검출하는 방법이고
HOG는 이미지의 gradient를 계산하여 histogram을 생성하고 bin들을 일렬로 이어 붙여 feature들을 생성하는 알고리즘입니다.
SIFT와 HOG로 Obejct를 검출할 경우, feature를 일렬로 늘어뜨릴 때 영상에 대한 위치 정보가 손실이 문제가 발생합니다.
그래서 이를 해소하기 위해 Sliding window 기법을 CNN에 접목한 방법인 OverFeat이 만들어졌습니다.
Overfeat은 고해상도 이미지로부터 만들어진 FC(Fully Connected) layer를 1x1 convolutional layer로 변환했습니다.
위 방법은 single forward 방식으로 CNN 모델을 학습한 후, Multi-scale evaluation을 통해 사물을 검출합니다.
하지만 single Sliding window로 Image Classification을 수행하면 탐색해야 하는 영역이 많아 연산량이 많아지고
시간이 오래걸리며 window의 stride에 따라 결과가 다르게 나타나는 문제점이 있습니다.
이러한 비효율성들을 개선하기 위해 등장한 것이 R-CNN입니다.
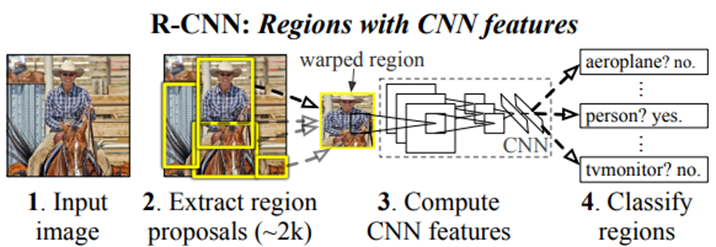
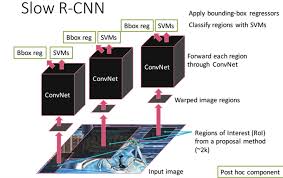
R-CNN은 다른 알고리즘들에 비해 성능과 속도가 좋은 Selective Search로 object가 있을법한 위치를 빠른 속도로 찾아내는 Region Proposal과 pre-trained AlexNet과 SVM을 거쳐 object를 식별하는 Region Classification으로 이루어진
2-Stage Detector입니다.
R-CNN이 Object Detection을 수행하는 과정을 보면 다음과 같습니다.
1. Selectvie Search로 약 2000개의 Region Proposal을 수행
2. SS로 부터 찾은 ROI를 이미지로부터 잘라내고 Warping한 후 CNN으로 Feature를 추출
3. 각 feature에 대한 Classification 및 Regression 수행
세부 내용을 살펴보겠습니다.
Segmentation과 Exhaustive search 두 가지를 수행합니다.

1. Segmentation 단계에서 위 사진과 같이 초기 영역을 랜덤하게 여러 개 생성
2. 탐욕 알고리즘을 사용하여 한 영역과 인접한 영역들 간의 유사도(size, color 등)를 비교하여 통합하는 과정을
반복적으로 수행하고 이렇게 통합된 영역들을 바탕으로 후보 영역들(~2k) 생성
(본 논문은 그림 4의 Final Detections까지는 수행하지 않습니다.)

하지만 Selective Search로 그림 5와 같이 label과 무관한 영역을 잡는다면 Classification에 대해 좋은 결과를 기대할 수 없게 합니다.
그래서 각 Region들의 Groundtruth에 대한 IoU를 계산을 수행하여 region들을 분류합니다.

IoU threshold를 0.3으로 설정하고 이보다 작으면 Negative example로 처리하여 region을 제거하고
같거나 크면 Positive example로 처리하여 예측한 Bounding Box의 영역만큼 Crop하고 뒤에 입력될 AlexNet 모델의 입력 이미지 크기에 맞게 Warping(resizing-227x227)합니다.
(일반적으로 사용하는 IoU threshold 0.5보다 0.3이 성능이 더 잘 나왔으므로 0.3을 채택합니다.)
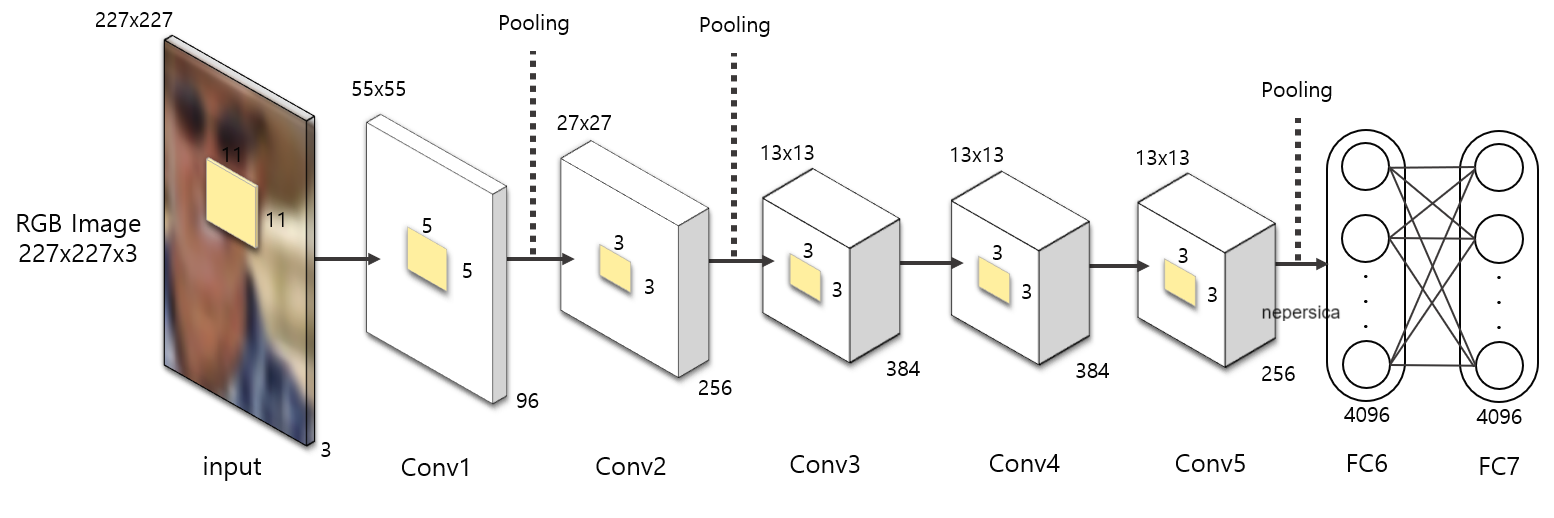
Selective Search로 만들어진 Positive example 데이터들을 pre-trained AlexNet에 적용하여 feature map을 추출합니다.
pre-trained AlexNet을 사용한 이유는 VOC 데이터의 양이 적어 학습이 잘 되지 않는 것을 방지하기 위해 ILSVRC 2012 ImageNet으로 학습된 AlexNet 모델에 VOC를 추가로 학습시킵니다.

AlexNet으로부터 추출된 feature map으로부터 각 class에 대한 Linear SVM을 진행하여 classifier를 학습시킵니다.

그리고 SVM을 통해 score 값들을 획득하는데 동일한 object 중 score가 가장 높은 bounding box만 남기고 나머지는 제거하는 Non-Maximum Suppression을 합니다.
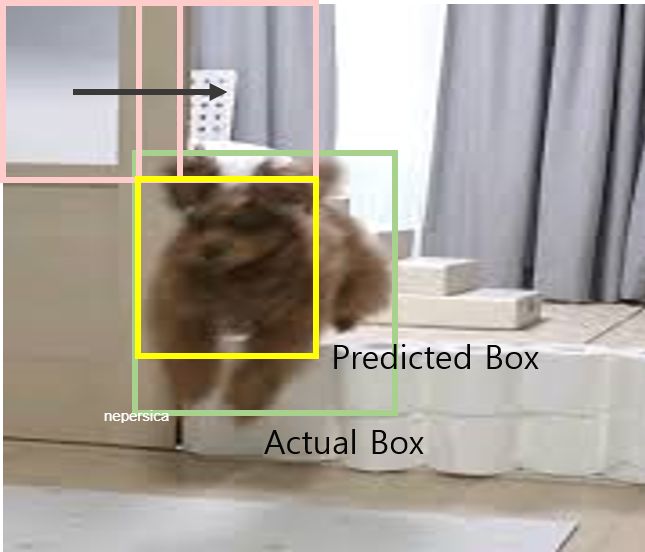
- Bounding Box Regression

결과적으로 남은 Selective Search로 임의로 예측한 Bounding box의 정보가 정확하지 않은 것을 고려해 Bounding Box에 대한 Regression을 수행합니다.

P는 예측해서 얻은 bounding box의 정보(x, y, w, h), G는 정답값의 정보
G hat은 최적화된 bounding box의 정보, 람다는 정규화 크기값 1000,
t는 P가 G로 조정되는 값을 의미합니다.
오른쪽 수식들을 사용해서 Regression을 하는 예를 들어보겠습니다.

다음과 같이 P(2, 2)와 G(5, 5)를 갖는 높이와 너비가 3인 Bounding Box가 존재합니다.
이때 P가 G만큼 이동 및 크기 조정할 때, t_x를 최적화하는 과정을 설명하겠습니다.
1번 과정을 통해 G_x만큼 P_x가 상대적으로 이동할 거리를 구하면 1이 나옵니다.
그리고 우리는 이 t_x에 근사하는 d_x(P)를 찾기 위해 Regression을 수행합니다.

d_x(P)는 학습 가능한 Initialized weight 벡터와 Regression 성능을 가장 잘 나오게 한 pool5 layer feature의 곱으로 구성합니다.
MSE로 t_x와 d_x(P) 간의 loss를 구하고 weight의 Overfitting을 방지하기 위해 L2 Normalization을 합니다.
이 과정으로 나온 값 weight hat으로 학습시킬 weight 벡터를 업데이트하고
업데이트된 dx_(P)를 기존 P의 정보를 사용하여 정보를 갱신해 P를 G에 최적화되도록 합니다.
Result )
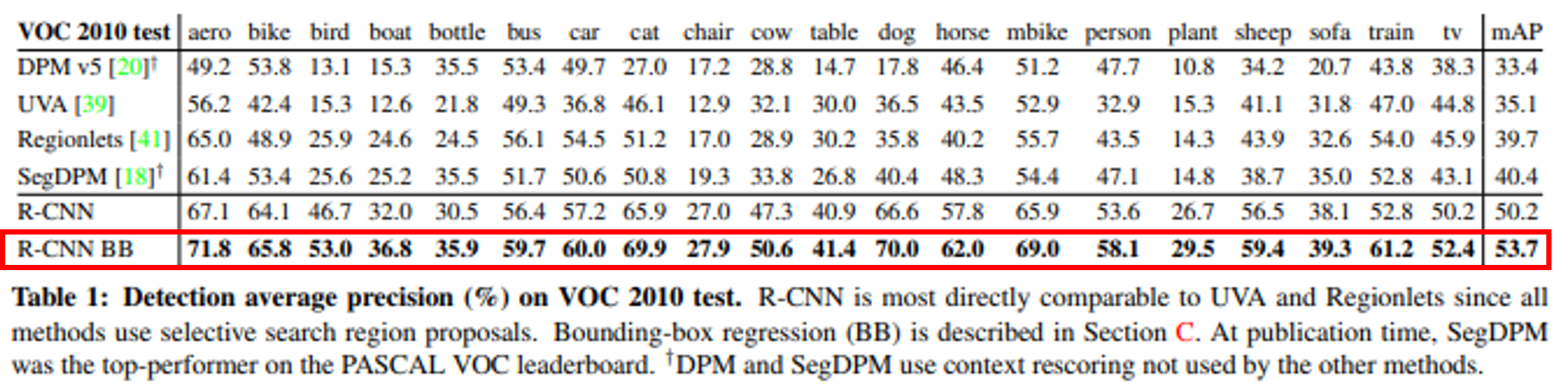
이전에 사용되었던 다른 모델들과 R-CNN에 bounding box regression을 포함하기 전, 후의 mAP를 비교했을 때,
R-CNN의 성능이 월등히 높은 것을 확인 가능했고
R-CNN에 bounding box regression이 포함된 모델의 성능이 더 좋은 것을 확인할 수 있습니다.
<Reference>
SIFT :bskyvision.com/21
Histogram: darkpgmr.tistory.com/116
'Deep Learning > Object Detection' 카테고리의 다른 글
| [Object Detection] YOLOv1 ~ YOLOv3 (0) | 2021.01.21 |
|---|---|
| [Object Detection] FPN: Feature Pyramid Network (0) | 2021.01.21 |
| [Object Detection] SPP-Net, Fast R-CNN, Faster R-CNN (0) | 2021.01.21 |