2021 Snowy Paper Project
안녕하세요.
오늘은 현재 제가 속해 있는 연구실 세미나에서 다른 분이 발표 했던 YOLOv1~YOLOv3에 대하여
매우 간단하게 정리만 할 예정이오니, 가볍게 읽고자 하시는 분들에게 도움이 될 것을 말씀 드리고 정리 시작합니다.
(노트 필기를 토대로 하는 것이므로 격식체로 작성하지 않는 점 죄송합니다)
1. YOLOv1(You Look Only Once)
- Background
2-stage method(RPN+Classification)은 Real-time Detection에 적합하지 않은 처리 속도
(Real-time detection은 보통 30 fps 이상의 처리 속도를 가져야 함.)
- Improvement
전체 이미지에 대한 Large context를 파악하며, RPN과 Classification을 병렬적으로 처리하는 1-stage detector 생성
- Contibution

º Unified Detection
: 이미지 한 장을 SxS 그리드로 분할 => 이미지의 크기가 448x448인 경우, 7x7 그리드 사용
각 gride cell 당 2개의 Bounding Box((x,y,w,h, confidence score) + class probability)를 가짐

º Network: GoogLeNet 기반 24 convolution layer + FC layer로 구성 됨.
→ Predict Tensor: 7x7x30

º Loss Function: multi loss

① Coordinate Loss
②-(a) Confidence Loss
②-(b) No-object Panelties
③ 각 grid가 갖는 Classification Loss
- Experiment

2-stage(Fast R-CNN, Faster R-CNN 등)에 비해 속도는 증가했지만 성능을 일정 수준 저하됨.
- Problem
º Group of small objects : 각 grid cell은 하나의 class만 예측 가능함.
→ 이미지에 나타나는 objects의 domain size는 반영 불가
→ Grid cell 하나보다 작은 크기의 Object 문제점
º Unusal aspect ratios: Training data에 한하여 Bbox를 학습하므로 새로운 형태의 Bbox를 정확하게 예측하지 못함.
º Localization error of Bbox
2. YOLOv2(Better, Faster, Stronger)
- Background
º Classfication task에 비해 적은 양의 data set을 보유함.
º Fewer Classess
→YOLOv1의 Problem 해결과 성능 향상을 목표로 함.
9000개의 class에 대한 Object Detection을 수행함.
- Contribution
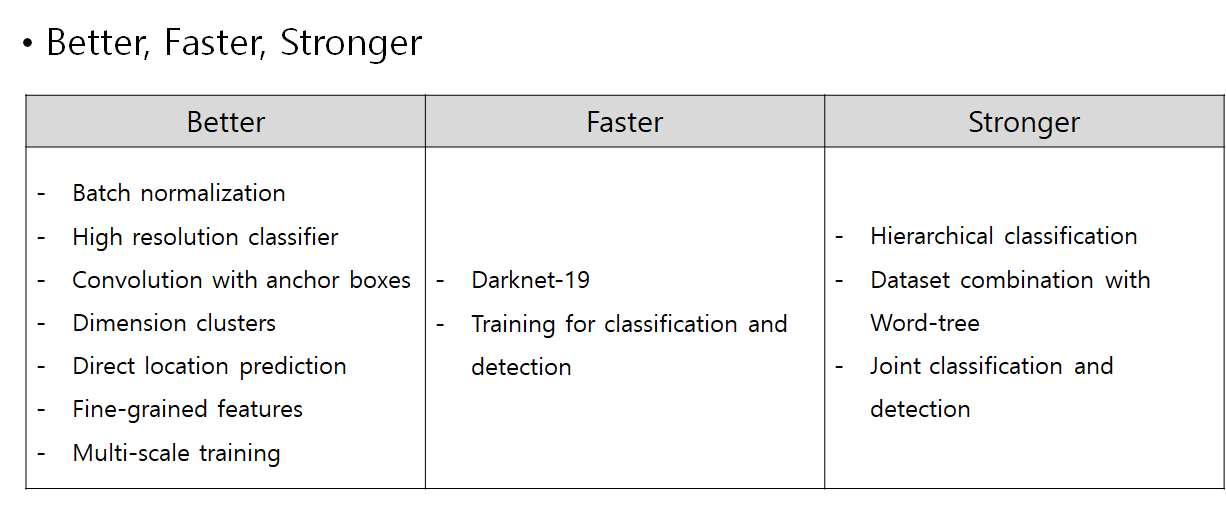
º Convolutions with Anchor Boxes
: 크기와 비율이 고정된 anchor box로 Training을 통해 크기 및 위치를 세부 조정함.
→ Sliding window의 각 위치에서 Bbox의 후보로 사용함.
(이미지 크기 416x416을 기준으로 13x13 gride와 5개의 Anchor box를 사용함.)

º Direct Location Prediction
: Bbox의 좌상단을 기준으로 이동해야 하는 거리를 예측함.
→ Bbox 중심 좌표가 하나의 grid cell 내에서만 이동할 수 있도록 함.
Anchor box의 w와 h의 조정 비율을 지수 승(exp)으로 예측함.

º Architecture
YOLOv1의 Backbone인 DarkNet-19와 GoogLeNet의 방대함과 복잡성을 지적함.
그래서, YOLOv1의 FC layer를 제거하고 Conv layer로 대체하여 FCN 구조로 변경함.
→ 19 convolution layers(3x3 filters) + 5 Max pooling layers,
Global Average Pooling을 사용하여 feature들을 1차원 벡터로 만들어 줌.
- Problem
Small object 또는 Overlapping된 Object에 대한 Localization error 발생
2. YOLOv3(An Incremental Improvement)
- Background
"Small changes that make it better"
- Contribution
º Class Prediction → multi-label classification for objects
: 각 class 별로 sigmoid를 취하여 binary classification을 적용함으로써 multilabel classification을 수행함.
: Hierarchical class에 대한 예측 ex) person과 woman을 동시에 예측

º Prediction Across Scale
: 총 3개의 Scale을 사용하며, 각 scale 당 3개의 anchor box를 가짐.

(+) Anchor Box: Training set을 바탕으로 K-means clustering을 적용하여 9개의 anchor box를 결정함.

→ 각 scale 당 3개의 anchor box를 할당함.
ex) 이미지 크기: 416x416일 때, stride = 32, 16, 8
- Network
DarkNet-19를 확장하여 DarkNet-53을 생성함.


- Experiment
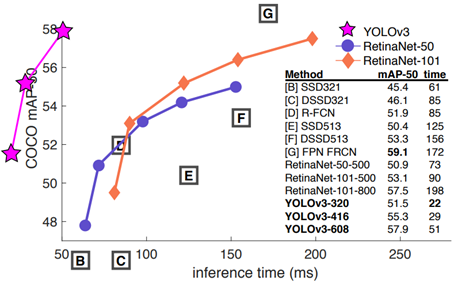

- Problem
→ Backbone Network를 Darknet-53으로 확장함에 따라 네트워크의 복잡성이 증가함.
→ YOLOv2에 비해 정확도는 상승하였으나 속도는 하락함.
'Deep Learning > Object Detection' 카테고리의 다른 글
| [Object Detection] FPN: Feature Pyramid Network (0) | 2021.01.21 |
|---|---|
| [Object Detection] SPP-Net, Fast R-CNN, Faster R-CNN (0) | 2021.01.21 |
| [Object Detection] R-CNN: Regions with CNN features (2) | 2021.01.21 |