
[Real-time Segmentation] YOLACT: You Only Look At Coefficients
안녕하세요.
오늘은 연구실 세미나 5주차에 제가 발표했던 Real-time Instance Segmentation 논문 YOLACT(You Only Look At Coefficients)를 간단하게 정리해보려고 합니다.
Bolya, Daniel, et al. "Yolact: Real-time instance segmentation."
Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019.
(논문 링크: https://arxiv.org/abs/1904.02689)
Keyword: Protonet, Prediction Head, Coefficient branch, Fast NMS
YOLACT는 2019년에 ICCV에 게재된 논문입니다.
YOLACT가 나오기 전, 기존 Segmentation model들은 Object Detection을 활용한 2-stage로 구성된 model들이 만들어졌고 성능에 중점을 두고 연구가 되었습니다.
그래서 본 논문은 성능이 아닌 속도에 중점을 둔 1-stage segmentation model을 제안했습니다.
YOLACT Architecture
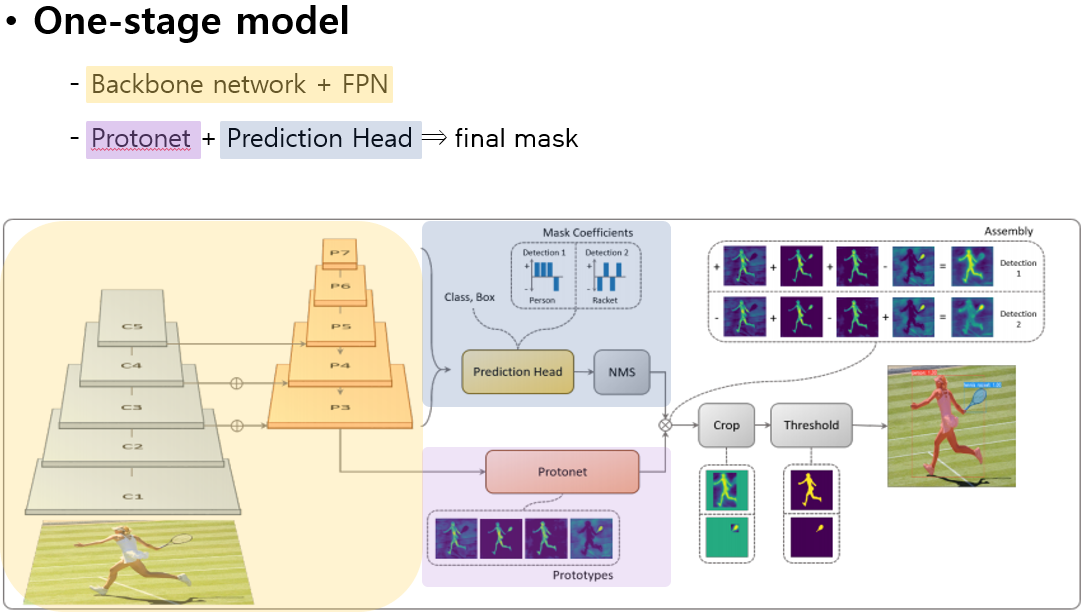
YOLACT의 network를 매우 간단하게 훑어 보면,
ResNet을 기반으로 한 BackBonet network와 FPN(Feature Pyramid Network)를 거쳐
병렬적으로 Protonet과 Prediction Head를 수행한 후 두 결과를 선형 결합하여 최종적인 final mask를 획득합니다.
그리고 YOLACT의 task를 자세하게 살펴보겠습니다.
Method
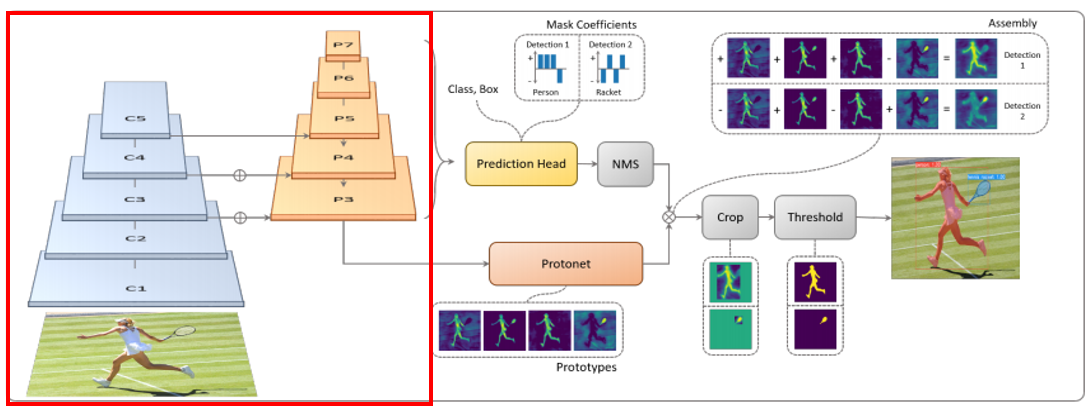
먼저, Backbone Network(ResNet)을 통과하여 5개의 feature map을 구성하고
이 feature map들을 활용하여 FPN에서 5개의 feature map을 생성합니다.
이렇게 생성된 FPN의 feature map들은 Protonet과 Prediction Head로 각각 들어가게 되는데요
task를 병렬적으로 수행하는 Protonet과 Prediction head 중 Protonet을 먼저 보겠습니다.
Protonet
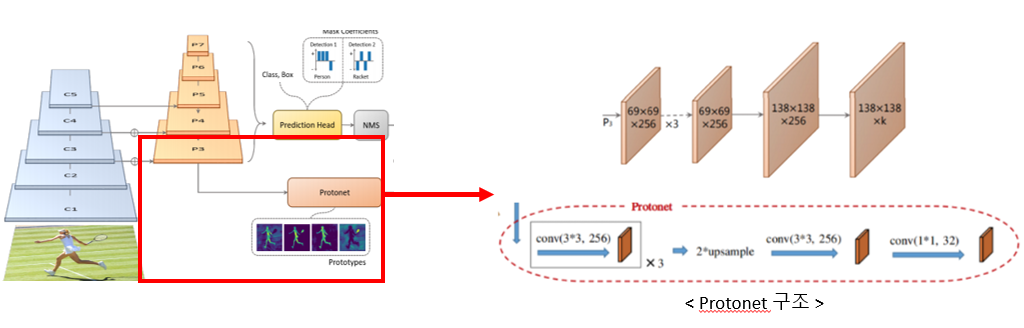
Protonet은 FPN에서 가장 Deep한 P3로부터 feature extraction을 추가 수행하여 138x138크기의 mask를 k개 생성하는데
feature extraction을 추가로 수행하는 이유는 padding을 활용하여 이미지의 특정 partition들을 activate시켜 네트워크가 instance를 localize할 수 있게 해줍니다.
그럼 어떻게 padding으로 partition을 activate하고 localize하는 것일까요?

예를 들어 좌측에 있는 파란색의 rectangle에 일반적인 conv 연산을 수행하게 되면 ouput의 pixel들은 모두 동일한 값을 갖는데,
이 파란색 rectangle에 아래 그림 4처럼 zero padding을 씌워주고 conv 필터 값을 임의로 조정하면 오른쪽 output처럼 특정 partition에 activate된 map을 획득하게 됩니다.
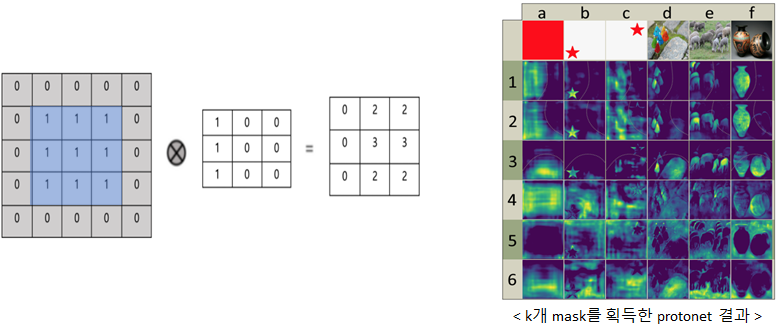
그래서 논문에 나와있는 오른쪽 그림처럼 partition에 치우져진 map을 획득할 수 있게 됩니다.
(예를 들어, k=1~3은 이미지 내 점선으로 표시된 곡선 안쪽 object를 activate시켰고 k=6은 이미지의 배경과 object 간의 edge를 activate시켰습니다.)
다음으로, Protonet과 병렬적으로 수행되는 Prediction Head을 보겠습니다.
Prediction Head
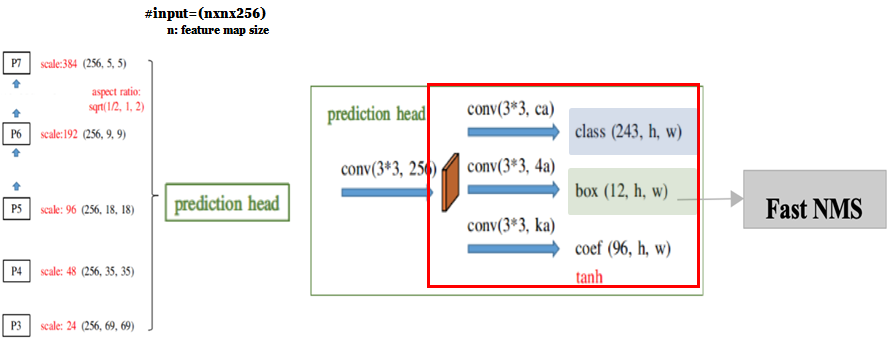
Prediction Head는 Protonet과 다르게 FPN의 feature map들을 모두 입력 받아 3x3 연산을 거친 후 class, box, coefficient branch 3개의 branch로 나뉘어집니다.
- Class branch
: feature map의 각 pixel마다 3개의 anchor box를 생성하고 각 anchor box마다 class에 대한 confidence를 계산합니다.
(ex. class num=80+background=81일 때, (81*3, n, n) shape를 획득하게 됩니다.)
- Box branch
: 3개의 anchor box에 대한 좌표 값(x,y,w,h)를 예측합니다. (4*3, n, n)
- Coefficient branch ~ YOLACT의 핵심인 branch인 coefficient branch입니다.
: 앞서 Protonet에서 k개의 prototype mask들이 특정 instance 1개에 대하여 localize하지 않은 것을 여기에서 수행해줍니다.
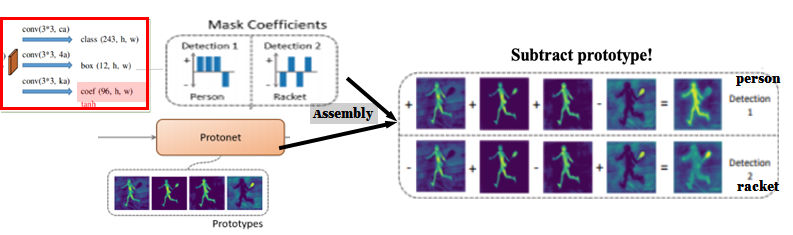
이 branch는 feature map의 각 anchor box가 instance 1개만 localize하도록 조정하여 k개의 feature map에 대한 coefficient를 예측합니다.
예를 들어, 그림 6에 있는 Mask Coefficients라고 적힌 밑을 보면 feature map으로부터
Detection 1은 Person에 대하여, Detection 2는 Racket에 대하여 localize한 결과를 갖는 것을 볼 수 있습니다.
(Person에 대한 Detection 1에서 4개의 feature map에 대하여 coefficient (1, 1, 1, -1)를 갖습니다.)
그리고 protonet에서 획득한 prototype mask와 mask coefficients를
instance에 대하여 k개의 prototype mask를 더하고 빼는 연산을 수행하여 mask를 획득합니다.(Assembly)
그림 6의 우측과 함께 보면,
k개의 prototype mask와 Detection 1에서 (1, 1, 1, -1)을 선형 결합하여 얻은 mask에는
instance Person에 대하여 extraction이 된 결과를 갖는 것을 확인할 수 있습니다.
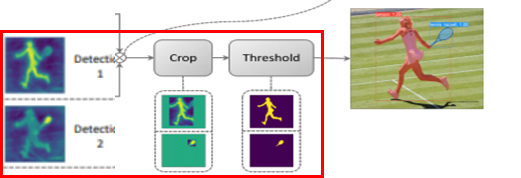
Assemble한 mask를 Prediction head의 box branch에서 예측한 box만큼
instance에 대한 segment를 Crop하고 IoU를 비교하여 final mask를 획득하게 됩니다.
Loss Function
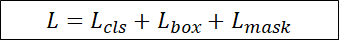
Loss function은 classification, box, mask loss들의 합으로 이루어져 있습니다.
classification과 box loss는 Softmax Cross Entropy가 사용되었고
mask loss는 mask의 groundtruth과 prediction의 Binary Cross Entropy로 구성되어 있습니다.
Fast NMS
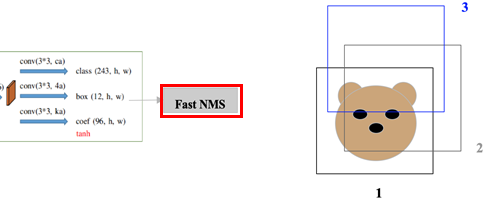
그리고 YOLACT에서는 일반 NMS가 아닌 Fast NMS를 사용했는데요,
일반 NMS와의 차이점은 fast NMS는 이미 제거된 anchor box가 또 다른 anchor box를 지우기 위해 비교를 계속해 나간다는 것입니다.
예를 들어 일반 NMS에서 1번과 2번 anchor box를 비교했을 때,
object에 대하여 1번에 비해 2번의 confidence가 낮고 둘의 IoU threshold가 만족되어 2번이 제거가 되고 이후 anchor box들을 NMS하는데 더 이상 개입을 하지 않습니다.
하지만 Fast NMS는 2번이 제거되었음에도 불구하고 일반 NMS와 다르게 3번 anchor box에 대하여 NMS를 수행할 때 개입되어,
2번은 3번에 비해 confidence가 높고 둘의 IoU threshold가 만족해 3번 anchor가 제거하게 됩니다.
Fast NMS를 사용하게 되면 일반 NMS보다 많은 anchor box를 제거하게 되어 약간의 성능 저하가 되는 단점이 있지만
행렬 연산을 수행함으로써 GPU를 사용하여 월등히 속도를 향상시킨다는 장점이 있습니다.
Conclusion

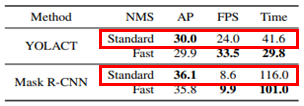
기존 Segmentation model들과 비교했을 때 더 robust한 mask를 획득하게 됩니다.
YOLACT는 성능이 아닌 속도에 중점을 두었기 때문에 속도, 성능 간의 trade-off가 존재하게 되어
MASK R-CNN보다 속도는 빠르지만 정확도는 떨어진 것을 확인할 수 있습니다.
그리고 YOLACT는 object가 많은 경우 detect를 하는데 어려움을 겪는 limitation이 존재합니다.

그래서 이 limitation을 해결하고 YOLACT의 구조를 개선시킨 BlendMask에 대해 다음 포스팅을 잇도록 하겠습니다.
'Deep Learning > Segmentation' 카테고리의 다른 글
| [Real-time Segmentation] PSPNet, ICNet, ENet (0) | 2021.01.21 |
|---|---|
| [Instance Segmentation] Mask R-CNN (0) | 2021.01.21 |
| [Semantic Segmentation] FCN: Fully Convolutional Network (0) | 2021.01.21 |